Bigtable について調査していたときに書いたメモです。
CAP 定理
整合性(Consistency)・可用性(Availability)・分断耐性(Partition Tolerance) の 3 つのうち、同時に 2 つしか満たせないことを明らかにした定理。証明も発表されているらしい。
整合性(Consistency)
いかなる読み出しに対しても最新の値を返す
- 整合性を保つ単位を原子オブジェクトと呼ぶ。
- 分散データベースは原子オブジェクトの範囲内で整合性をもたせる
可用性(Availability)
いかなる時刻に到達したクエリでも実行可能
- ある更新クエリが実行されている間、他のクエリを待たせた場合は、可用性が失われている
分断耐性(Partition Tolerance)
ノード間の通信が遮断されていてもデータベースとして動作可能
RDB は CA 型のデータベース。分散データベースの場合、分断耐性が必須となるため、CP 型か AP 型の 2 択となる。 read 重視 (いかなる時でも最新の値を取得したい) なら CP 型、write 重視 (絶対にカートに入れる操作を成功させたい)なら AP 型?
CP 型の DB
CP 型の DB では一つの原子オブジェクトに対して一つのマスターノードを割り当てる。これによって整合性を担保できるが、そのマスターノードがダウンすると、マスターノードが管理していた原子オブジェクトは更新不可 (=可用性が失われる) となる
具体例
- BigTable
- HBase
- MongoDB
AP 型の DB
AP 型の DB では全てのノードがあらゆる原子オブジェクトのクエリを受け付ける。そのため、いかなる時でもクエリが実行できる。一方で分断時に 2 つのノードで同一の原子オブジェクトの更新が行われた場合は、データの不整合が生じる。そのため後で不整合を修復する必要がある
具体例
- DynamoDB
- Cassandra
- CouchDB
NoSQL の文脈で CAP 定理を考えるなら、P を軸にした場合、C と A はトレードオフの関係にあると解釈すると良さそう。 C と A のレベル感とアプローチは DB によって異なるため、C と A の二者択一で考えるのは止めたほうが良い気がする。あくまでも NoSQL を考える観点の一つとして捉える。
参考ドキュメント
NoSQL の分類
- NoSQL は 4 種類に分けられる
- 列指向型 (ワイドカラムストア)
- キーバリュー型
- ドキュメント指向型
- グラフ型
- BigTable はワイドカラムストアに分類される
BigTable とは
大規模分散 NoSQL データベース
- スケーラブル
- 数ペタバイトのデータを保存可能
- 低レイテンシ・高スループット
- フルマネージド
BigTable の論文をもとに開発されているソフトウェアとして、HBase (CP 型) がある。可用性を求めるなら Cassandra がある。
アーキテクチャ
- BigTable は インスタンス > クラスタ > ノードの 3 層構造になっている
- 1 つのインスタンスに 1 つ以上のクラスタがあり、1 つのクラスタに 1 つ以上のノードがある
- あるクラスタに対してレプリケーション用のクラスタも作成できる
クラスタは以下の三要素で構成される
- Front-end server pool
- Node
- Colossus
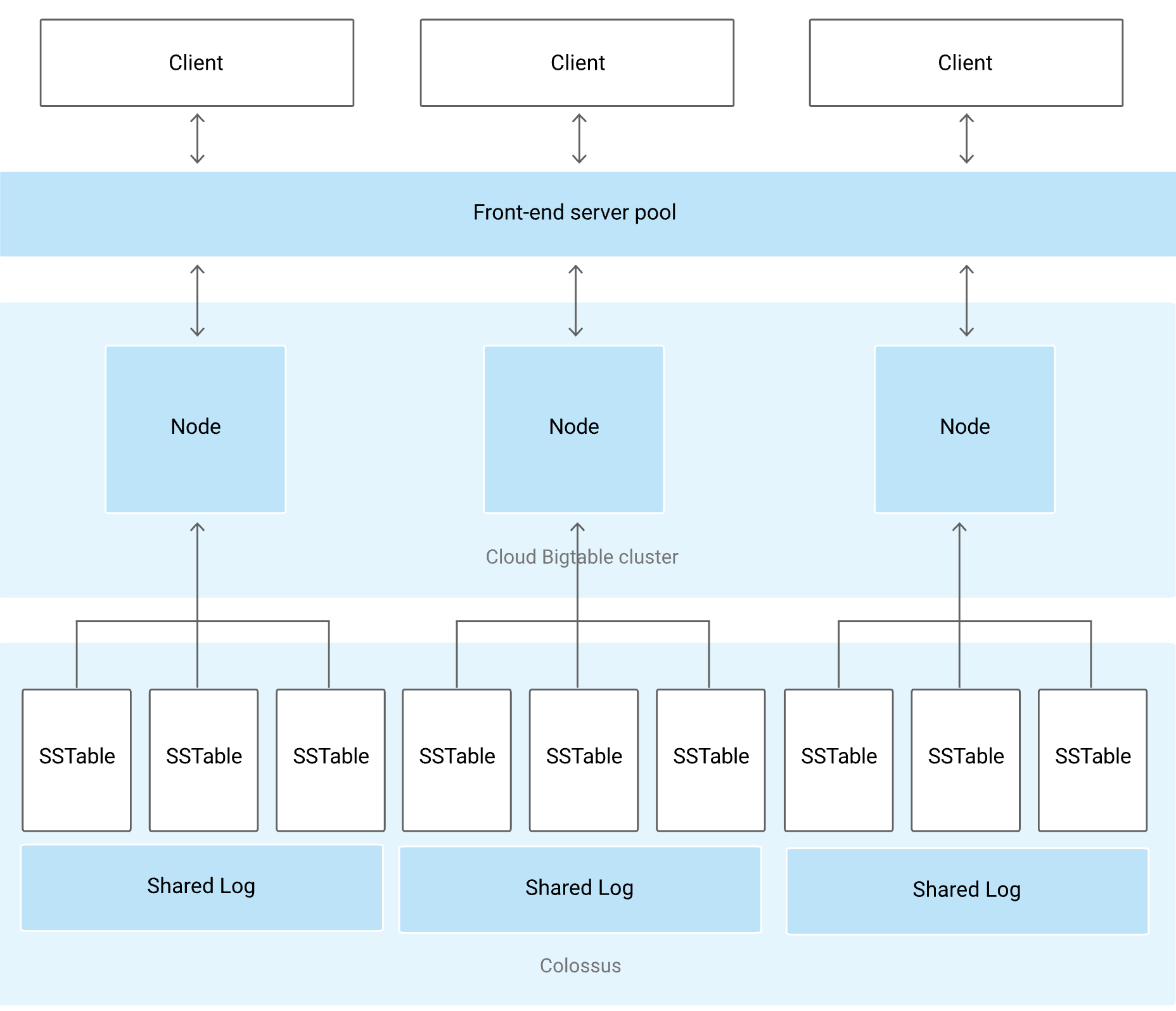
各要素の説明と特徴
- Front-end server pool はクライアントからのリクエストを各ノードに振り分ける
- 一つのノードに対し、複数の行ブロック(タブレット)を割り当て
- タブレットを各ノードで分散して保持 → クエリの負荷分散を実現
- タブレットは SSTable 形式で保存
- SSTable に書き込まれるだけでなく、Colossus にも shared log として保存
- shared log を持つことで耐久性が向上
- ノードではなく、Colossus がデータを保持しているのが特徴
- ノードはタブレットのセット(集合)に対するポインタを保持するのみ
- メリット
- ノード間での行ブロックの移動が高速化できる
- 障害復旧が高速に実行できる
- ノードで障害が発生してもデータが失われない
マルチクラスタと整合性
単一クラスタの BigTable インスタンスでは、強整合性(定義通りの整合性)が保証される一方、複数クラスタの場合は、結果整合性(データ書き込み後に古いデータを読み出されることを許容)が保証されるようになっている。
- レプリケーションには遅延があり、すべてのクラスタに最新の値が反映されるまでにはラグがある
- レプリケーションを使わない場合は強整合性を担保できる
- https://cloud.google.com/bigtable/docs/replication-overview#consistency-model
データ構造
BigTable は以下のようなデータ構造をしている todo: 後で列キー → 列修飾子に変える

列:実際の値が格納される- 列の名前は
列修飾子と呼ばれる
- 列の名前は
列ファミリー:関連する列をグループ化する行:BigTable の原子オブジェクト- 各行は基本的に Key-Value エントリの集合
- キーとは、列ファミリー・列修飾子・タイムスタンプを連結したもの
- 行で使用されていない列は存在しないものとみなされ、余計なメモリを消費しない
セル:行 x 列で特定できるデータ- 複数のセルを格納することが可能
スキーマ設計のポイント
列ファミリー
- 関連する列は一つにまとめる
- 1 テーブルにつき、作成する列ファミリーは 100 個までとする
- 列ファミリーの名前は短くする (転送されるデータに含まれる)
- ニーズが異なるデータは別の列ファミリーにする
- 例えば、ガベージコレクション (古くなったり、不要になったセルを自動で削除するための機能) は列ファミリー単位で管理される
- ↑ のことを踏まえて考えると、
最新バージョンだけ保持すれば良いデータ・複数バージョン保つ必要があるデータで列ファミリーを分けると良い
列・セル
- 列修飾子にデータを含めるとセルのサイズを節約できる。
- テーブルに対しては、行あたりの上限 (256MB) を超えない限り、いくらでも列を足して良い
- 行単位では、あまり列の数を増やさないほうが良い
- セルの処理時間がかかる
- セルに対してオーバーヘッド (追加データ) があるため、できるだけ一つのセルにデータを格納したほうが良い
- 一つのセルに対して 10 MB を超えるデータを保存しない
- 列で保持できるセルの数は列ファミリーに設定したガベージコレクションポリシーで管理できる
行
- 一行あたり 100MB を超えるとパフォーマンスが低下するらしい
- エンティティに関するデータはできるだけ一行に収めるようにする。
- BigTable のアトミックなオブジェクトは行
- 一つの行でエンティティを定義するようにする
- 複数行でエンティティを格納していた場合、更新があった際にデータの一部が不完全になる可能性がある。
行キー
asia#india#bangaloreのような形式で設定する- 複数の識別子を組み合わせると便利
先頭の値:カーディナリティ低、末尾の値:カーディナリティ高となるようにキーを設定する- デバイスの種類 → デバイス ID→ タイムスタンプ みたいな感じにすると良い
- BigTable は辞書順にデータを格納
- 範囲スキャンがしたい場合は、上述のようなキー設計にするとクエリの効率が上がる。
- 文字列の辞書順なので、数字をキーに配置する場合は注意 (1, 11, …, 19, 2, 21,… のような順番になる)
- 逆に UUID のようなカーディナリティが高い値を行キーの先頭に置いた場合、 範囲スキャンの効率は下がる
ホットスポット
- 上述の通り、BigTable は辞書順にデータを格納する。そのため、タイムスタンプや連続して番号が振られているユーザー ID のような値は同一ノードに書き込まれる。
- その結果、読み取り時に同一ノードにアクセスが集中 (ホットスポット) し、パフォーマンスが低下する
- できるだけ連続した値を行キーの先頭で使わないようにする